Linux提供了非常丰富的手段,供我们来评估一个进程的内存占用。top,/proc/[pid]/status,/proc/[pid]/statm等等。什么RSS,RES,VIRT,到底哪个才是真正的进程使用内存量?
有没有简单的手段直接就能知识一个进程的内存占用?很遗憾地说,没有。因为内存的使用,本来就不简单。
但是我们可以找到相对简单的方式。
进程的内存分布
我们要先从进程的内存分布说起。Linux下,一个进程的内存分布如下:
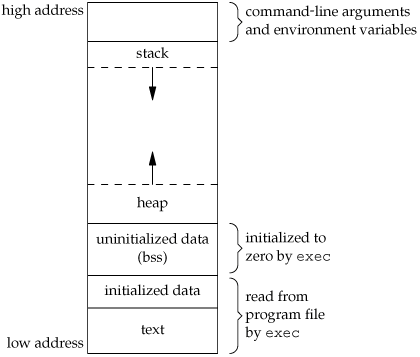
从低到高,分别包括:
- 文本段,也叫代码段,是对象文件或内存中程序的一部分,其中包含可执行指令。通常代码段是共享的,对于经常执行的程序,只有一个副本需要存储在内存中,代码段是只读的,以防止程序以外修改指令。
- 初始化的数据段,是程序的虚拟地址空间的一部分,它包含有程序员初始化的全局变量和静态变量,可以进一步划分为只读区域和读写区域。例如,C中的char=“hello world”的全局字符串,以及main(例如全局)之外的int debug=1这样的C语句。
- 未初始化的数据段,通常称为bss段,这个段的数据在程序开始之前有内核初始化为0,包含所有初始化为0和没有显示初始化的全局变量和静态变量,
- 堆,堆是动态内存分配通常发生的部分。堆是由程序员自己分配的(malloc kmalloc等)。堆区域由所有共享库和进程中动态加载的模块共享。
- 栈,存放临时变量,以及每次调用函数时调用栈。每当调用一个函数时,返回到的地址和关于调用者环境的某些信息的地址,比如一些机器寄存器,就会被保存在栈中。然后,新调用的函数在栈上分配空间,用于自动和临时变量。
要评估一个进程的内存占用,就是要把以上几个段的内存占用一一加起来。
Linux环境下内存信息的几个来源
/proc/[pid]/status
此文件包含了有关内存使用情况的重要信息,以Vm为前缀。
- VmPeak / VmSize:最大/当前进程正在占用的内存总大小。听起来不错,但实际上,这并不是一个好的评估内存的数据的办法。因为它包含了 1)申请但实际上未使用的内存。(malloc一段地址空间,但不使用它) 2)共享库使用的代码段地址空间,会被多个进程的VmSize同时统计。即存在重复统计的问题。
- VmHWM / VmRss:最大时/当前应用程序正在使用的物理内存的大小。没有被交换到swap的内存。是评估进程内存使用量的重要依据。
- VmData:包含initialized data+bss+heap。通常不准确,原因是heap的大小不准确。系统常常出于优化性能的考虑,多申请栈空间。
- VmExe:代码段中不包含lib的部分,即进程可执行文件的部分
- VmLib: 代码段中lib的部分。
VmSize = VmRss + 申请但未使用的内存块
/proc/[pid]/smap
这个文件反应了运行时的进程的在内存中的完整分布。这是一张完整的清单。通过它可以看到对应进程所关联的所有的内存信息(包含共享的,和私有的)
smap示例:
1 | 7fc4d49df000-7fc4d49e1000 rw-p 001eb000 08:01 2102913 /lib/x86_64-linux-gnu/libc-2.27.so |
几个关键字段:
- Rss:是进程的物理内存占用,包括进程本身和所有链接库,RSS = private + share
- Pss:链接库的共享内存平摊计算后的使用内存,(比如一个动态库有5个人引用,则将其代码段和共享内存除于5),PSS = private + share / share_num
- Shared_Clean:和其他进程共享的未改写页面
- Shared_Dirty:和其他进程共享的已改写页面
- Private_Clean:未改写的私有页面页面
- Private_Dirty:已改写的私有页面页面
其中:
private = private_clean + private_dirty: 这个数据一般能够比较准确反映一个进程内部占用的内存,在内存优化的时候使用这个作为参考值比较合理,进程的物理内存占用就是smaps中所有的private的相加(链接的动态库的也要统计进去)。
总结
- /proc/[pid]/status中,VmSize 因包含重复统计和未实际使用的内存,存在夸大的情况。VmHWM / VmRss 是相对理想的内存评估依据。
- 想要得到确定的内存使用量,将/proc/[pid]/smap中的所有Private_Clean和Private_Dirty累加起来,是很好的解决方案。

