本文说明如何一步一步地编译出自己的Hello World应用(插件),并部署到OpenWrt设备上。
准备工作
编译环境
准备编译环境,准备一个用于编译插件的根目录(我的环境中目录名是~/openwrt_plugins),在此目录下,下载OpenWrt工程到一个名为source的目录,并切换到最新的稳定版分支。
1 | git clone https://github.com/openwrt/openwrt.git source |
下载软件包
运行./scripts/feeds update -a命令,下载或更新在feeds.conf/feeds.conf.default中定义的所有最新软件包。
受限于国内的访问国际互联网的连接环境,feeds update这一步特别容易失败。可以通过以下几条方式来提高成功率:
git config --global http.postBuffer 524288000git config --global http.lowSpeedLimit 1000git config --global http.lowSpeedTime 600
以上配置的含义为:配置git缓冲区为500M,配置git访问超时的条件为:速率小于1KB/s,且持续600秒
运行./scripts/feeds install -a命令使安装上述软件包在后续的make menuconfig中生效。
配置编译选项
使用已有固件的编译配置
网络上已编译出的固件通常都会把编译配置一并提供(config.buildinfo或config.seed),可以直接使用。
我的目标机是一台小米WR30U,使用mtk的filogic芯片方案,从OpenWrt官网找到对应的编译配置并下载,置于OpenWrt工程根目录下的.config文件中:
1 | wget https://downloads.openwrt.org/releases/23.05.0/targets/mediatek/filogic/config.buildinfo -O .config |
但这份配置中包含了filogic芯片方案的所有设备的配置,还需进行裁剪和修改。
menuconfig
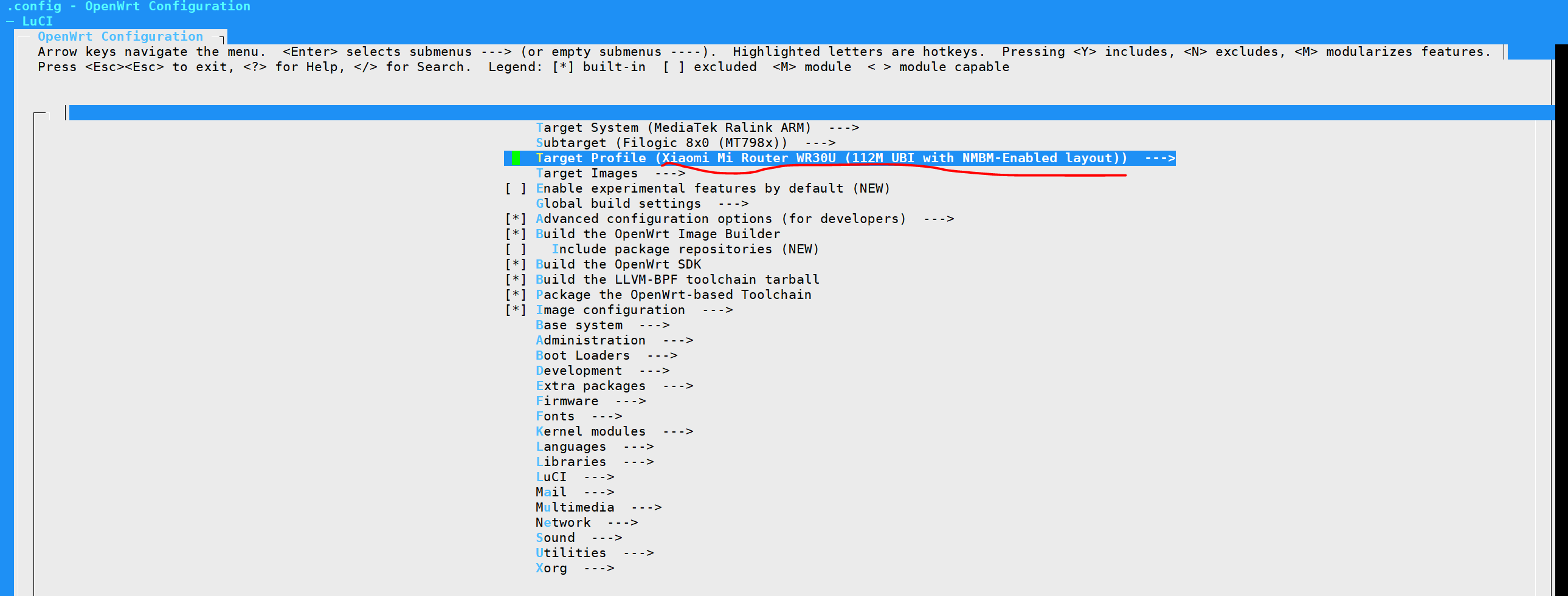
在以上配置的基础上,运行make menuconfig命令来完成进一步的自定义配置。完成后配置会更新至.config文件中。
在Target Profile中,仅保留Xiaomi WR30U的设备支持(我的设备是Xiaomi Mi Router WR30U (112M UBI with NMBM-Enabled layout)),把其它设备的支持删除。
编译工具链
根据以上的配置,编译出适配指定设备的编译工具链。
1 | make toolchain/install |
为了更高效地使用工具链中的各类工具,将工具链的输出目录加入PATH路径。
1 | export PATH=~/openwrt_plugins/source/staging_dir/host/bin:$PATH |
创建自己的OpenWrt应用
构建包(package)
OpenWrt构建系统在很大程度上围绕着“包”(packages)的概念展开。它们是系统的核心要素。不论是什么软件,几乎总会有相应的包。这适用于系统中的几乎所有内容,无论是与目标独立的工具、交叉编译工具链、目标固件的Linux内核、与内核模块,还是将安装到目标固件的根文件系统的各种应用程序。
因此,对于“Hello, World!”应用程序来说,也要遵循这种基于“包”的构建逻辑。
包源(package feed)是一个包的仓库,它包含包的配置项,可包含在最终固件中。包的仓库可以位于本地目录上,也可以位于网络共享上,或者可以位于GitHub之类的版本控制系统上。
下面,我会从源码构建出一个名为“helloworld_package”的包。
准备编译目录和源码
准备编译目录和代码,这里只准备一个最简单的Hello World程序。把以下代码存放至~/openwrt_plugins/helloworld_package/helloworld/source/helloworld.c文件中。
1 | #include <stdio.h> |
makefile存放至~/openwrt_plugins/helloworld_package/helloworld/source/makefile
1 | # Global target; when 'make' is run without arguments, this is what it should do |
清单文件,清单文件也是Makefile文件,用于指定包编译的各类信息:~/openwrt_plugins/helloworld_package/helloworld/Makefile
1 | include $(TOPDIR)/rules.mk |
feeds准备、更新、安装
在OpenWrt工程源码目录下~/openwrt_plugins/source,创建feeds.conf,文件内容如下:
1 | src-link helloworld_package /home/user_name/openwrt_plugins/helloworld_package |
注意,src-link这里不能写
~/openwrt_plugins/helloworld_package,要写绝对路径。
feeds更新与安装:
1 | cd ~/openwrt_plugins/source |
打印出这句话,就是安装成功了。
1 | Installing package 'helloworld' from helloworld_package |
编译package
通过make menuconfig把helloworld包给使能(位置在Examples/Hello, World!),并将配置保存。
然后执行以下命令编译:
1 | make package/helloworld/compile |
编译成功后,在bin/packages/<arch>/helloworld_package/目录下,可以看到ipk文件,就是编译出来的包了。
部署和应用
将编译出的ipk文件传输到设备上,通过opkg命令安装。
1 | opkg install /tmp/helloworld_1.0-1-arch>.ipk |
安装成功后,执行它。
1 | root@OpenWrt:~# /usr/bin/helloworld |
至此,一个最简单的OpenWrt应用就编译部署完成了。